Kappa Architecture
“How to beat the CAP theorem ?” - Lambda Architecture
Nathan Marz wrote a popular blog post describing an idea he called the Lambda Architecture. The Lambda Architecture is an approach to building stream processing applications on top of MapReduce and Storm or similar systems which is widely accepted as of now.
How does it look like ?

The Lambda Architecture is aimed at applications built around complex asynchronous transformations that need to run with low latency (a few seconds to a few hours). An immutable sequence of records is captured and fed into a batch system and a stream processing system in parallel and the transformation logic is implemented twice, once in the batch system and once in the stream processing system. Later we stitch together the results from both these systems at query time to produce the required answer.
We can swap in various similar systems for Kafka, Storm, and Hadoop, and also use two different databases to store the output tables, one optimized for real time and the other optimized for batch updates.A lot of variations are possible.A simple usecase will be a news recommendation system that needs to crawl various news sources, process and normalize all the input, and then index, rank, and store it for serving.
Pros & Cons of Lambda Architecture
Pros
- The Lambda Architecture emphasizes retaining the input data unchanged.
- It highlights the problem of reprocessing data - Reprocessing (processing input data over again to re-derive output) is one of the key challenges of stream processing : for e.g. during code change.
- Emphasise that real-time processing is inherently approximate, less powerful, and more lossy than batch processing( with latency/availability trade-offs in stream processing)
- The Lambda Architecture somehow “beats the CAP theorem” by allowing a mixture of different data systems with different trade-offs
Cons
- Maintaining code that needs to produce the same result in two complex distributed systems is painful : Programming in distributed frameworks like Storm and Hadoop is complex and also the code ends up being specifically engineered towards the framework it runs on.
- Any new abstraction can only provide the features supported by the intersection of the two systems
- The uber-framework walls off the rich ecosystem of tools and languages that makes Hadoop so powerful (Hive, Pig, Crunch, Cascading, Oozie, etc)
- The operational burden of running and debugging two systems is going to be very high
Questions That Raise Are..
- why can’t the stream processing system just be improved to handle the full problem set in its target domain?
- Why do you need to glue on another system?
- Why can’t you do both real-time processing and also handle the reprocessing when code changes?
- Stream processing systems already have a notion of parallelism; why not just handle reprocessing by increasing the parallelism and replaying history very, very fast?
What is “Kappa architecture”?
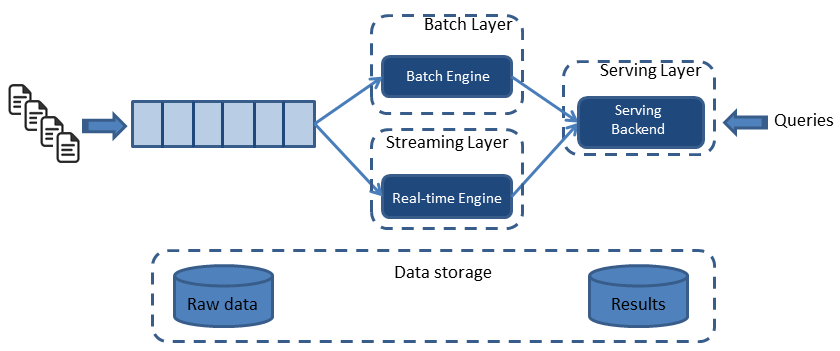 Figure 1. Lambda architecture. Figure courtesy of Ignacio Mulas Viela and Nicolas Seyvet.
Figure 1. Lambda architecture. Figure courtesy of Ignacio Mulas Viela and Nicolas Seyvet.
The Lambda architecture is composed of three layers: a batch layer, a real-time (or streaming) layer, and a serving layer. Both the batch and real-time layers receive a copy of the event, in parallel. The serving layer then aggregates and merges computation results from both layers into a complete answer.
The batch layer (aka, historical layer) has two major tasks: managing historical data and re-computing results such as machine learning models. Computations are based on iterating over the entire historical data set. Since the data set can be large, this produces accurate results at the cost of high latency due to high computation time.
The real-time layer( speed layer, streaming layer) provides low-latency results in near real-time fashion. It performs updates using incremental algorithms, thus significantly reducing computation costs, often at the expense of accuracy.
The Kappa architecture simplifies the Lambda architecture by removing the batch layer and replacing it with a streaming layer. A batch is a data set with a start and an end (bounded), while a stream has no start or end and is infinite (unbounded). Because a batch is a bounded stream, one can conclude that batch processing is a subset of stream processing. Hence, the Lambda batch layer results can also be obtained by using a streaming engine. This simplification reduces the architecture to a single streaming engine capable of ingesting the needed volumes of data to handle both batch and real-time processing. Overall system complexity significantly decreases with Kappa architecture.
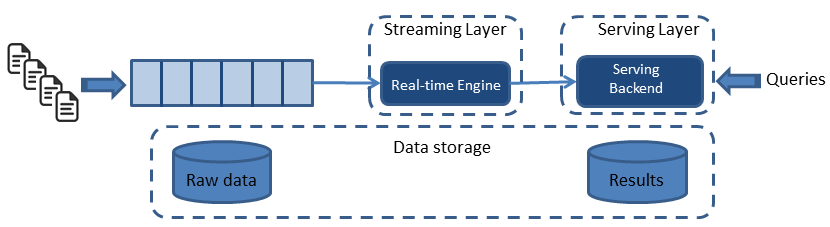 Figure 2. Kappa architecture. Figure courtesy of Ignacio Mulas Viela and Nicolas Seyvet.
Figure 2. Kappa architecture. Figure courtesy of Ignacio Mulas Viela and Nicolas Seyvet.
Main Principles of Kappa
- Everything is a stream: Batch operations become a subset of streaming operations. Hence, everything can be treated as a stream.
- Immutable data sources: Raw data (data source) is persisted and views are derived, but a state can always be recomputed as the initial record is never changed.
- Single analytics framework: Keep it short and simple (KISS) principle. A single analytics engine is required. Code, maintenance, and upgrades are considerably reduced.
- Replay functionality: Computations and results can evolve by replaying the historical data from a stream.
Building the Analytics Pipeline
TBD.
References
Questioning Lambda CAP Theorem Real-Time-Unifying Samza Applying-the-Kappa-Architecture