Hadoop & YARN
HDFS Federation
Hadoop 2.x introduces HDFS Federation, a scaling mechanism for the NameNode. The new Hadoop infrastructure provides multiple NameNodes, as opposed to the single NameNode used in Hadoop 1.x, and enables the NameNodes to work independently of each other. This offers two key benefits:
-
Scalability: NameNodes can now scale horizontally, allowing for the improved performance of NameNode tasks by distributing reads and writes across a cluster of NameNodes.
-
Namespaces: Multiple Namespaces can be defined, allowing for better organizing and separating of big data.
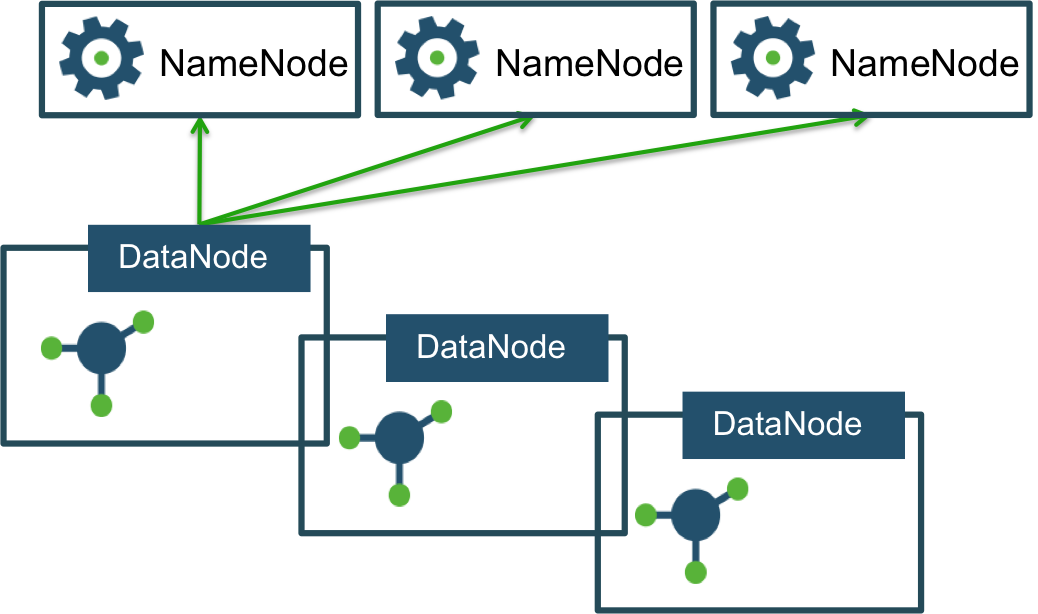
Multiple Federated NameNodes
The NameNodes are federated, which means they are independent and don’t require coordination with each other. DataNodes are used as common block storage by all NameNodes. Each DataNode registers with all NameNodes in the cluster and sends periodic heartbeats and block reports. Any NameNode can send commands to any DataNode.
Multiple Namespaces
All files and directories belong to a Namespace. In older versions of Hadoop, an instance had only a single Namespace. Hadoop 2.0 now allows for multiple Namespaces, with each NameNode managing a single Namespace. Multiple Namespaces offer:
-
Scalability - Having multiple independent Namespaces makes scaling possible in Hadoop 2.0.
-
File Management - It is now possible to associate Big Data with a Namespace, which makes it easier to manage and maintain files.

HDFS High Availability
Prior to Hadoop 2.0, the NameNode was a single point of failure in an HDFS cluster. Each cluster had a single NameNode, and if that machine or process became unavailable, the cluster as a whole would be unavailable until the NameNode was either restarted or brought up on a separate machine.
The HDFS High Availability (HA) feature addresses this issue by providing the option of running two redundant NameNodes in the same cluster in an Active/Passive configuration with a hot standby. The Quorum Journal Manager (QJM) allows a fast failover to a new NameNode during hardware failure or administrator-initiated failover for planned maintenance.
- Quorum Journal Manager
Two separate machines are configured as NameNodes, one in an Active state, the other in a Standby state. The Active NameNode handles all cluster client operations, while the Standby acts as a slave, maintaining state to provide a fast failover if necessary.
Both nodes communicate with a group of separate daemons called JournalNodes. All Namespace modifications are logged durably to a majority (a quorum) of the JournalNode daemons. When the Standby Node checks the edits in the JournalNodes, it applies them to its own namespace.
** Note: In the event of a failover, before switching to Active state, the Standby must read all of the edits from the JournalNodes. This ensures that the Namespace state is fully synchronized before a failover occurs. **
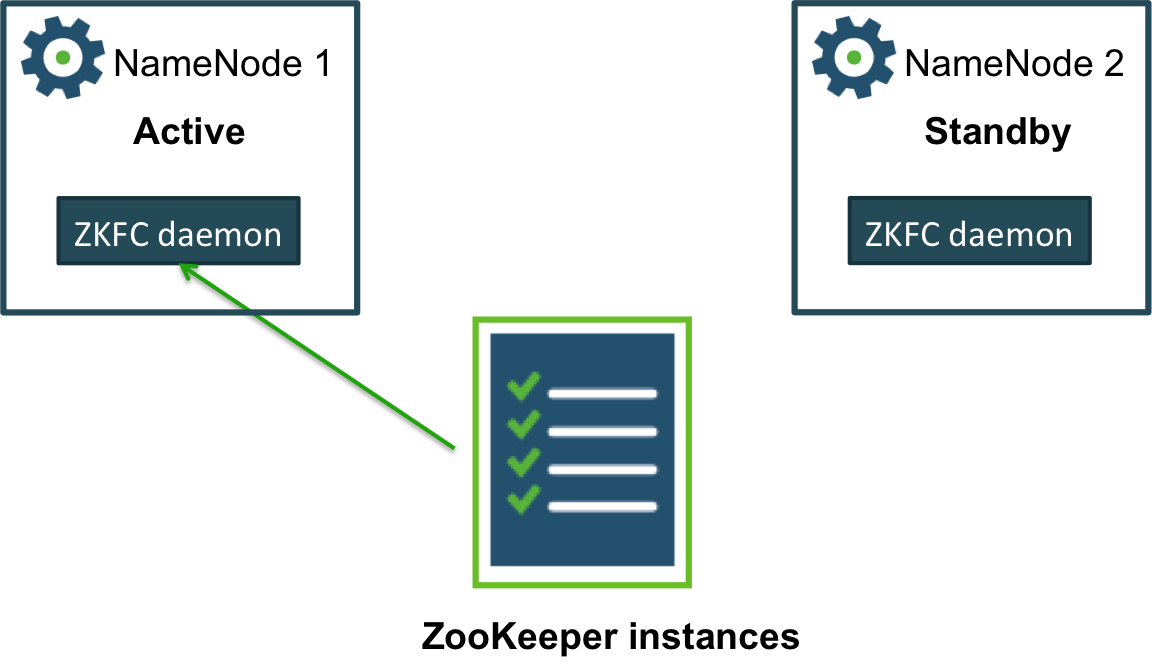
- Configuring Automatic Failover
Quorum Journal Manager only provides a manual failover. To enable HA NameNodes to failover automatically, ZooKeeper and the ZKFailoverController (ZKFC) must be configured within the cluster. ZooKeeper runs an odd number of daemons that monitor if a NameNode fails. ZKFC is a ZooKeeper client that monitors and manages the state of a NameNode.
Each machine with a NameNode runs a ZKFC instance. The ZKFC periodically pings the NameNode with a health-check command. If the NameNode responds with a healthy status, ZKFC continues normally. If the NameNode has crashed or become unresponsive, ZKFC will mark it as unhealthy.
YARN
Yet Another Resource Negotiator (YARN) extends Hadoop beyond just MapReduce for data processing. Although it is still able to execute MapReduce jobs across the cluster, YARN further provides a generic framework that allows for any type of application to execute on the big data.
Opensource YARN Use Cases
Since YARN enables Hadoop to run applications beyond MapReduce, there are countless possibilities for the types of processing that can be done on data stored in HDFS. Below is just a brief list of open-source projects currently being ported onto YARN for use in Hadoop 2.0. More frameworks will be developed as YARN becomes more prevalent.
| Tez | Improves execution of MapReduce jobs. |
|---|---|
| HOYA | HBase on YARN. |
| Storm and Apache S4 | For real-time computing. |
| Spark | A MapReduce-like cluster computing framework designed for low-latency iterative jobs and interactive use from an interpreter. |
| Open MPI | A high-performance Message Passing Library that implements MPI-2. |
| Apache Giraph | A graph-processing platform. |
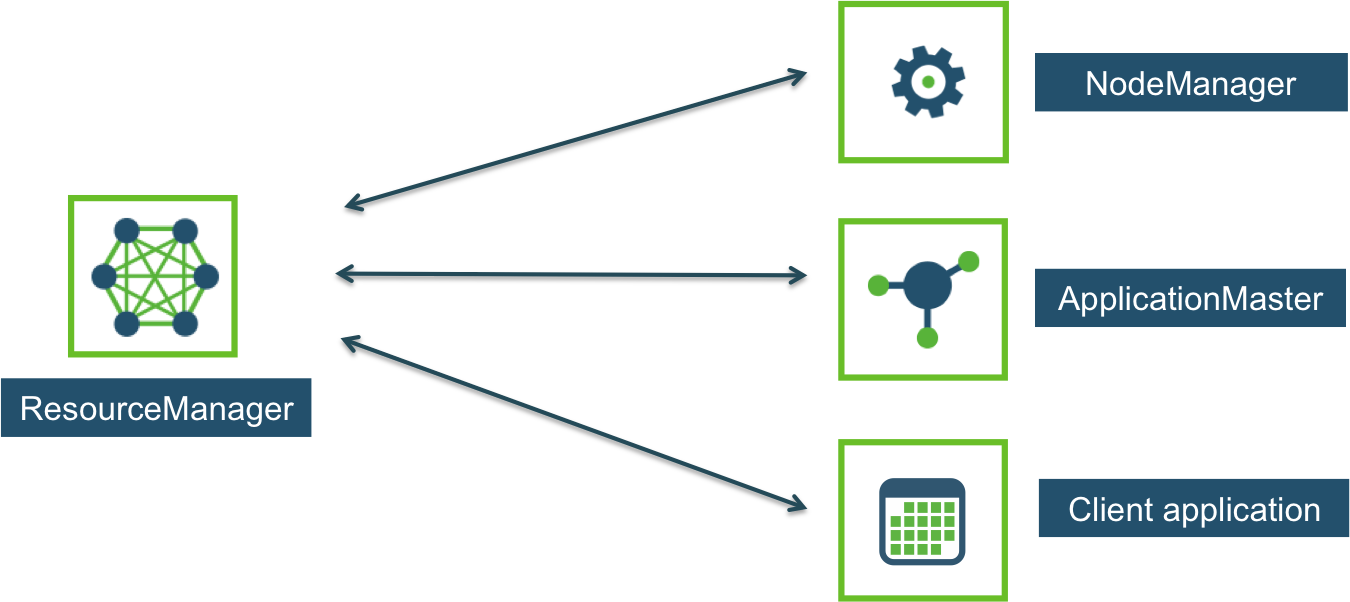
YARN Components
YARN consists of the ResourceManager, the NodeManager, and the ApplicationMaster.
-
ResourceManager is the central controlling authority for resource management and schedules and allocates cluster resources. It has a pluggable scheduler that allows for different algorithms (such as capacity and fair scheduling) to be used as necessary. It is a pure scheduler that does not monitor or track application status or restart failed tasks due to application or hardware failures. ResourceManager also tries to optimize the cluster (i.e. use all resources all the time) based on the constraints of the scheduler. In medium to large clusters it typically runs on a dedicated machine.
-
The NodeManager is the per-machine slave. It runs on the same machines as the HDFS DataNodes. It is responsible for launching the applications’ resource containers (CPU, memory, disk, network), monitoring their resource usage and reporting the same to the ResourceManager.
-
Each per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the ResourceManager, tracking their status, and working with the NodeManager(s) to execute and monitor the component tasks. The ApplicationMaster has primary responsibility for application fault tolerance. Because each application has its own ApplicationMaster, it is not a common bottleneck for the cluster. Each ApplicationMaster runs in a container on a NodeManager machine.
** Note : There is no JobTracker in Hadoop 2.x. YARN’s ResourceManager and ApplicationManager replaced the Hadoop 1.x JobTracker functionality. There is no TaskTracker in Hadoop 2.x. YARN’s NodeManager replaced the Hadoop 1.x TaskTracker functionality. **
Lifecycle of a YARN Application
The YARN lifecycle
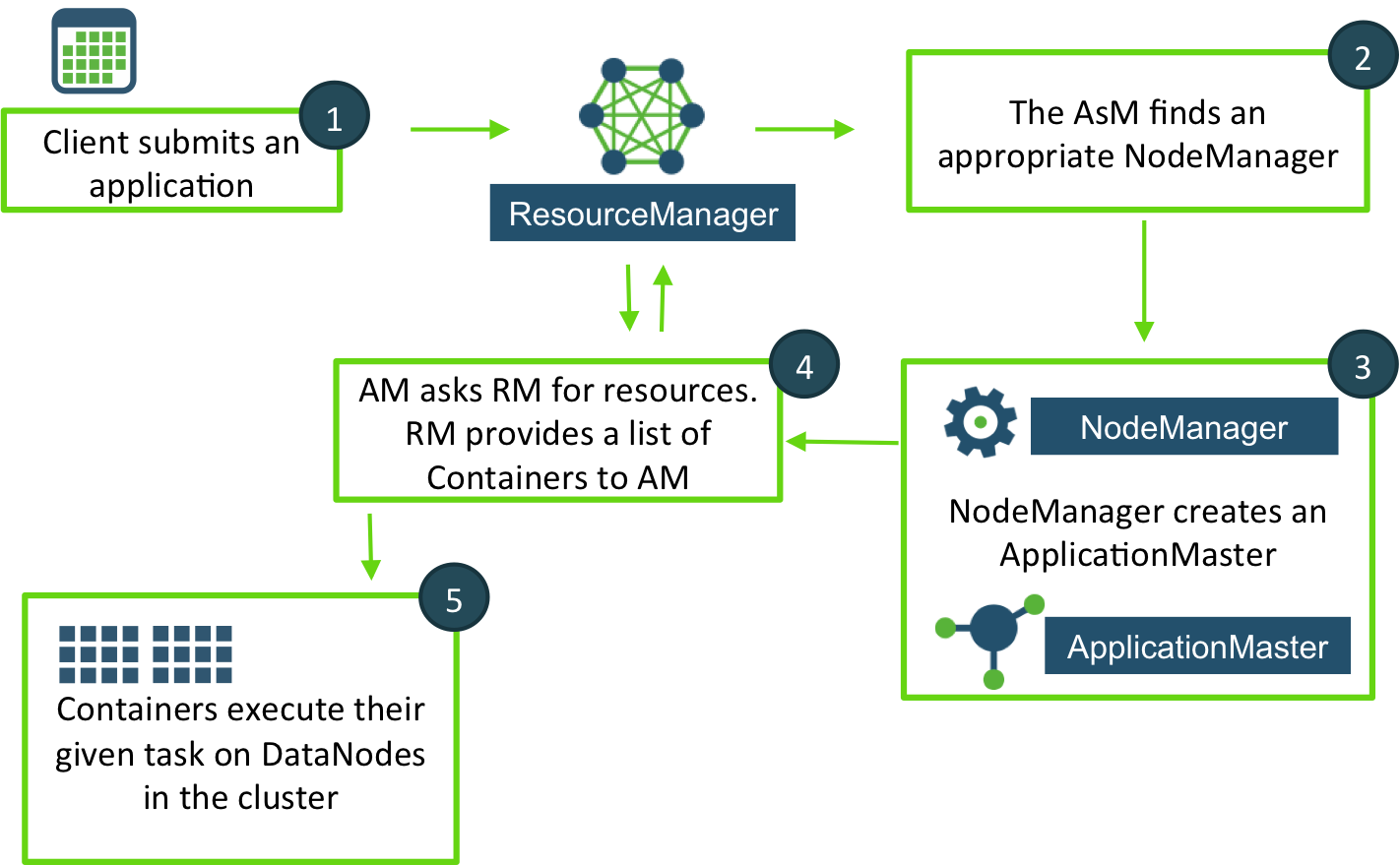
1) A client application submits a new Application Request to the ResourceManager (RM).
2) The ApplicationsManager (AsM) finds an available DataNode on the cluster.
3) That node’s NodeManager (NM) creates an instance of the ApplicationMaster (AM).
4) The AM then sends a request to the RM, asking for specific resources like memory and CPU requirements. The RM replies with a list of Containers, which includes the specific DataNodes to start the Containers on.
The AM starts a Container on each DataNode as instructed by the RM. The Container performs a task, as directed by the AM. As tasks are being performed by the Containers, the client application can request status updates directly from the ApplicationMaster.
Reference www.hortonworks.com*