Benchmarking Kafka
Kafka is composed by producer, broker and consumer. HDP cluster only holds kafka broker, however producer and consumer more often imbeds in application implementation, and they take majority influence on entire Kafka performance. The following benchmark is based analysis on a few production grade clusters on HDP.
Kafka Producer
Kafka producer benchmark focusing on batch.size and linger.ms
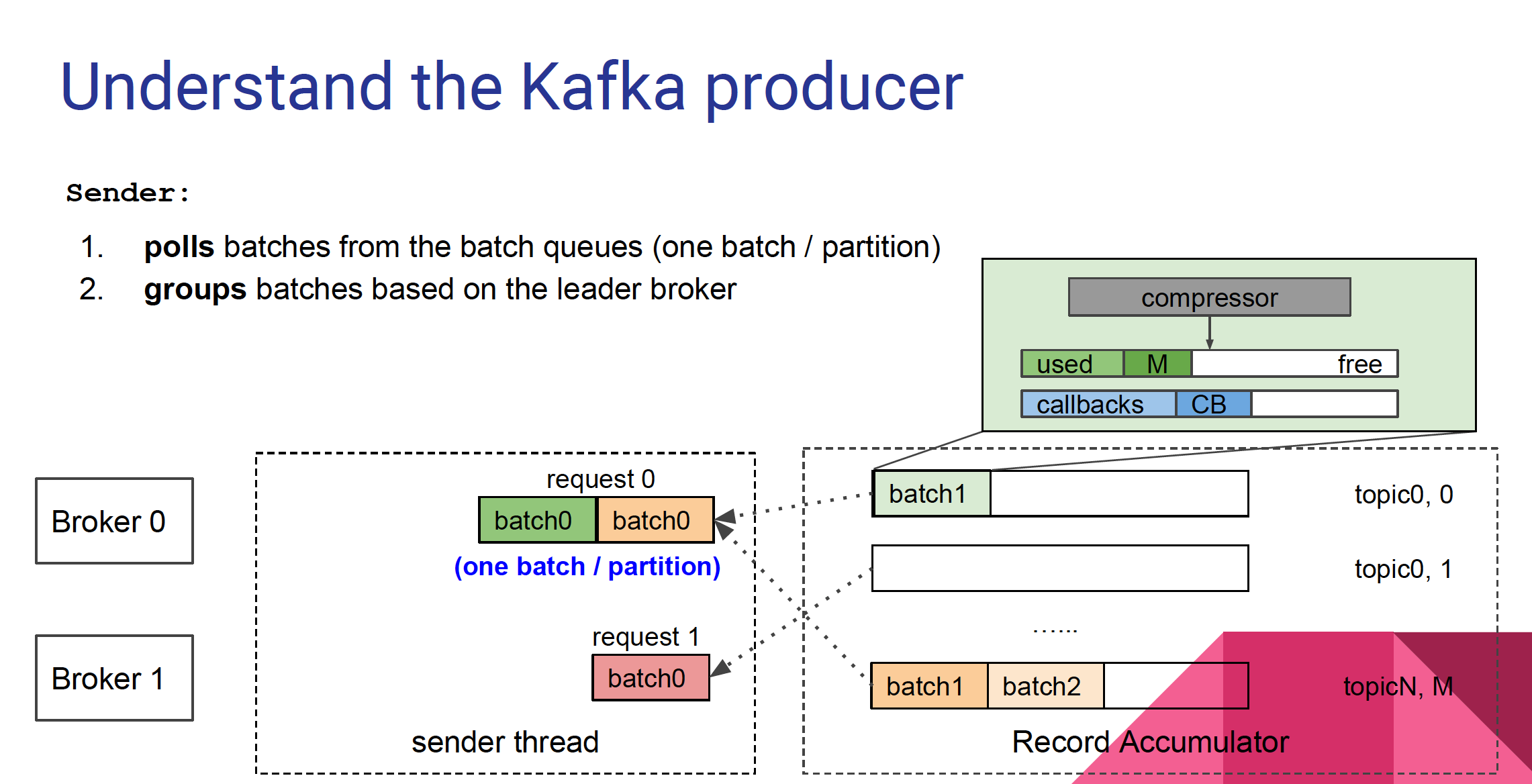
Batch.size A small batch size will make batching less common and may reduce throughput (a batch size of zero will disable batching entirely). A very large batch size may use memory a bit more wastefully as we will always allocate a buffer of the specified batch size in anticipation of additional records.
Linger.ms The producer groups together any records that arrive in between request transmissions into a single batched request. Normally this occurs only under load when records arrive faster than they can be sent out. However in some circumstances the client may want to reduce the number of requests even under moderate load. This setting accomplishes this by adding a small amount of artificial delay—that is, rather than immediately sending out a record the producer will wait for up to the given delay to allow other records to be sent so that the sends can be batched together. This can be thought of as analogous to Nagle’s algorithm in TCP. This setting gives the upper bound on the delay for batching: once we get batch.size worth of records for a partition it will be sent immediately regardless of this setting, however if we have fewer than this many bytes accumulated for this partition we will ‘linger’ for the specified time waiting for more records to show up. This setting defaults to 0 (i.e. no delay). Setting linger.ms=5, for example, would have the effect of reducing the number of requests sent but would add up to 5ms of latency to records sent in the absence of load.
The relationship b/w batch size and throughput can be depicted by the following curve. When batch.size is increased by 10,000, the average throughput start increasing marginally, and keeps at 5 MB/sec or so. When batch.size grows by 2500, the average latency stop increasing and stay at 6 ms around.
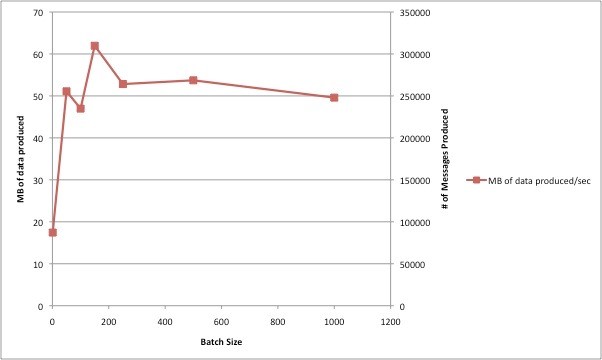
** Capture the average throughput and delay when gradually increasing batch size - use the kafka-producer-perf-test.sh scripts for the same.
./kafka-producer-perf-test.sh -num-records 5000000 -record-size 1000 -topic testkafka -throughput 100000 -num-threads 2 -value-bound 5000 - print-metrics - producer-props bootstrap.servers=x.x.x.x:6667 compression.type=gzip max.in.flight.request.per.connection=1 batch.size = 2000 security.protocol=SASL_PLAINTEXT
By tuning linger.ms we can promote the glaring gap.
####Kafka Consumer
Kafka consumer focus on fetch-size and throughput.
Use the below command to get the required metrics -
java -Djava.security.auth.login.config=/temp/kafka_jaas.conf \ -Djava.security.krb5.conf=/etc/krb5.conf \ -Djavax.security.auth.useSubjectCredsOnly=true \ -cp /usr/hdp/current/kafka-broker/libs/scala-library-2.11.8.jar:/temp/consumer/jopt-simple-5.0.4.jar:/usr/hdp/current/kafka-broker/libs/*:/temp/consumer/kafka_2.11-1.1.0-SNAPSHOT.jar kafka.tools.ConsumerPerformance \ --new-consumer --broker-list 10.0.0.18:6667 --topic chen --messages 5000000 --fetch-size 1000000 --show-detailed-stats --from-latest --print-metrics \ --consumer.config /usr/hdp/2.6.1.0-129/etc/kafka/conf.default/consumer.properties
fetch-size <Integer: size> controls the number of bytes of messages to attempt to fetch in one request to the Kafka server.
Messages <Long: count> Required: the number of messages to consume
This gives the below information -
- Throughput [MB.sec]
- For each 5 second iteration the number of newly consumed messages [data.consumed.in.nMsg]; which is aligned record size set in producer
- Recieved messages [data.consumed.in.nMsg]
- Calculate --> records-consumed-rate ~ (records-per-request-avg)*(fetch-rate)
- Calculate --> bytes-consumed-rate ~ (fetch-size-avg)*(fetch-rate)
Check if by reducing fetch-size down the throughput increases